PyCPA: 会計データ基盤の話
6 月 4 日に PyCPA という勉強会で大規模サービスにおける会計データ基盤について話した。
https://pycpa.connpass.com/event/246420/
MAU 1,000 万人超の消費者向け大規模サービスにおいて、会計データの収集・集計を目的とした社内向けシステムの開発運用に携わった経験をもとに、会計データを処理するシステムに特有の課題、およびその解決方法の選択肢とトレードオフについてお話しします。
人数の制限や当日の都合で参加できなかった方のために、話した内容とその背景、補足をここに書き残しておく。随分と時間が経ってしまってすみません。
より詳しく聞きたいという方がいたらご連絡ください。
概要
複雑な「お金の動き」を伴うサービスを開発・運用するとき、それをどのような方法で正確・迅速に捕捉し財務会計や管理会計に必要なデータとして収集・保存・集計するべきかという課題がある。
この課題を解決するための既製品がない場合、会計データ基盤を自社または外注で開発・運用することになる。このとき、資金や人員等の制約、サービスの置かれた状況に応じて様々な選択肢が考えられる。
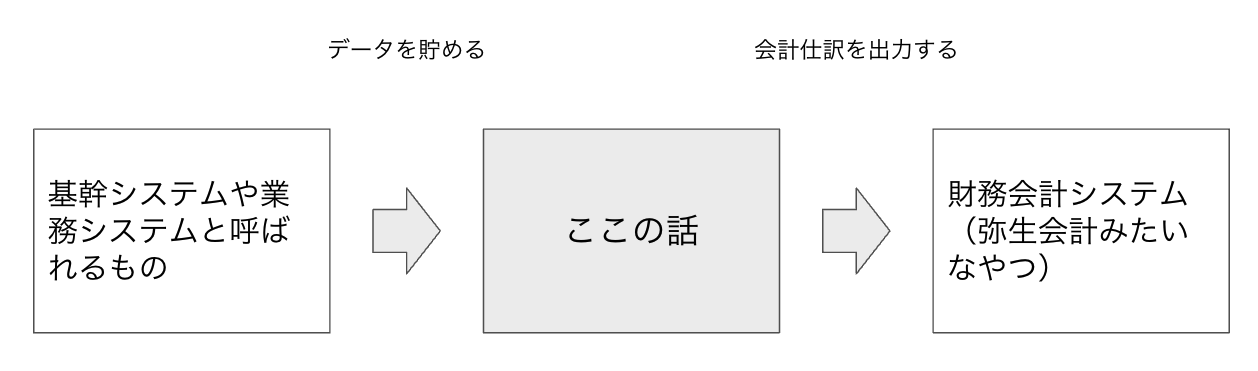
ここでいう「会計データ基盤」とは、弥生会計や freee、マネーフォワードのような財務会計システムではなく、それらに入力するための会計処理データを基幹システム等から収集・集計・保存・出力するシステムを指すものとする。会社によっては会計 I/F とか会計システムとか様々な名前で呼ばれているようだ。
この記事では、私が大規模なフリマアプリを運営する会社で会計データ基盤の担当者として働いた経験をもとに、以下の三点について書く。
- 会社が成長する過程でどのような会計データ基盤が作られたか
- それぞれの方法の pros/cons
- 会計データ基盤を作る際の方針をどのように立てるのがよいか
なお、以下の点については触れない。
- 購買に伴う請求書や立替経費など領収書のデータ化
- 給与計算などに伴う人件費のデータ化
前提: フリマアプリの話
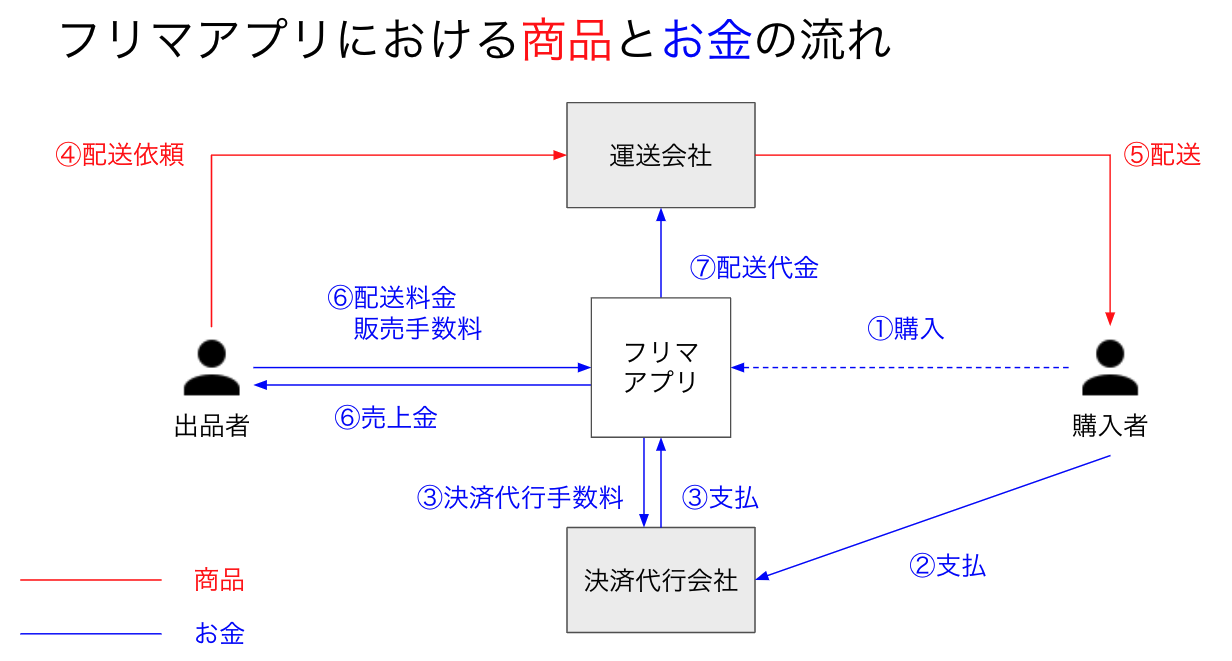
勉強会当日はフリマアプリを題材として取り上げたが、ご存知ない方もいると思われるのでフリマアプリの主な商品とお金の流れについて書く。
取引は次のような順序で進む。
- 出品者の商品が購入される
- 購入代金がクレジットカードほか様々な決済手段を通じて支払われる
- 決済代行会社を通じて支払われたことが確認される。この資金は決済代行手数料を控除され、予め決められたサイクルで入金される
- フリマアプリが出品者に商品の配送を依頼し、出品者は自身が選択した方法で配送手続を行う
- 配送会社によって商品が購入者に届けられる
- 購入者が商品を受け取った旨をアプリを介して出品者に通知する。その後、購入者と出品者がお互いを評価して取引が完了し、出品者は売上金を受け取る。このとき一定の販売手数料が控除される。アプリに組み込まれた配送手段で配送依頼した場合は、配送料も控除される
- 配送会社に配送代金を支払う
実際には決済代行会社や配送会社との取引条件は場合によって異なるので正確に上記の順序通り進む訳ではないが、大まかに説明するとこのような商流となる。
なお、取引の過程で何らかのイレギュラーな事象が発生する場合もある。例えば、取引が途中でキャンセルされたり、配送途中で商品が破損したり、決済が不正に行われチャージバックされた等の理由から、通常の商流とは異なるお金の流れが発生することがある。一日数十万件の取引が行われていると、必ずどこかしらでイレギュラーが発生している。
正常な流れ、イレギュラーな流れのそれぞれに対して会計処理が必要となるので、その証拠となる元データを収集し保存しなければならない。
もし読者が全く異なる事業を営む会社で働いていたとしても、自社のお金の流れを想像しながら適宜読みかえていただけるとありがたい。
お金の動きを整理するときのコツ
上記のような商流を整理するときは、まず取引に直接または間接的に関わる利害関係者を全員書き出すとよい。お金の流れとはすなわち債権債務の発生と消滅なので、利害関係者のそれぞれに対していつ債権債務が発生しいつ消滅するかを考えていくと漏れにくい。
しかし、実際にお金が流れる点だけに注目すると見落としがちな論点もあるので、社内外の会計専門家にレビューをしてもらうことをお勧めする。例えばポイント引当金(利用者に付与したポイントの将来利用額を見積もって費用/負債として計上する)のような、実際に利害関係者の間で現金の動きはないものの損益として計上する…というような会計処理は見落としやすい。
ある程度整理できたら、それぞれのお金の流れを証明するデータがどこにどのような形で存在するのか、どうすれば効率的に集計できるのかを一つ一つ調べていく。会計の要件が完全に考慮された上でデータ構造が設計されていれば特に困ることはないのだが、設計時に見落とされている、もしくは優先度が下げられていることもある。データ構造を変更することは難しい場合が多いため、既存のデータ構造を使いながら頑張って複雑な SQL を書いて集計しなければならなくなるかもしれない。
データが揃ったら、商流を積み重ねて作った財務モデルに実際のデータを回帰的に当てはめてみて、その結果があるべき残高と一致しているか勘定科目ごとに確認する。例えばフリマアプリであれば、利用者の売上金残高を上記のデータから再現し、それを実際の残高と比べてみる。
ここで不整合があれば、原因を調査し解決したあと同じ手順を再度繰り返す。
どのような会計データ基盤が作られたか
前述のお金の流れを集計するために作られた会計データ基盤のアーキテクチャと、それが会社やサービスの成長に従って生じた様々な課題にどのように対処したかについて書く。
まず何から始めるか?
会計に必要なデータの集計には本番に保存されているデータを使うものの、負荷やセキュリティ上の理由から直接本番の DB に集計クエリを投げるわけにはいかない。
そのため、必要なテーブルを dump しておき、バッチ処理で別の DB や DWH にインポートして集計するという方法が一般的と考えられる。このとき、必要に応じてデータを加工することがある。
例えば個人情報は会計データの集計には不要であり、漏洩リスクを抑えるためにも dump する前に削除しておくことが望ましい。また、本番のデータ構造が集計に不向きな場合には dump 後に集計用の中間テーブルを作ることが考えられる。
最初にできた会計データ基盤は以下のようなシンプルな構成だった。
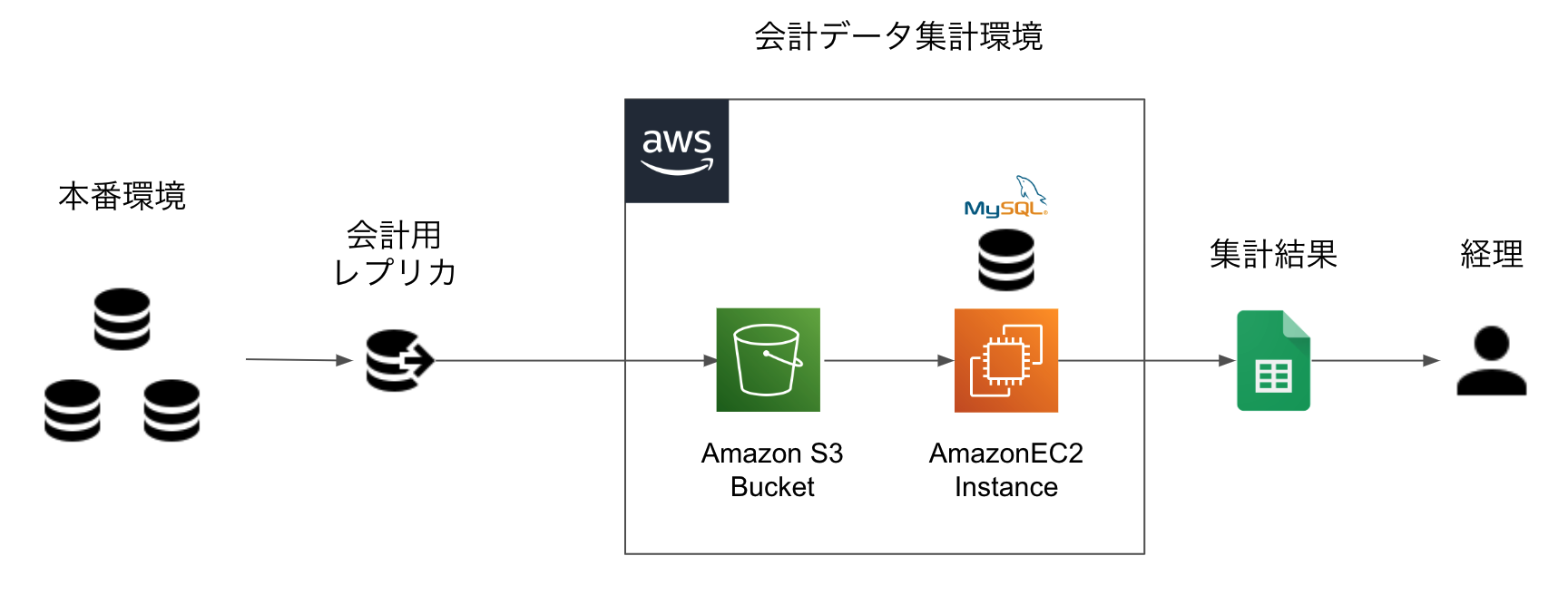
- 日次で本番環境の DB が replicate される
- 1 日の終わりに replication を停止し、個人情報を削除して dump し S3 に upload する
- 集計するタイミング(通常は月次)で EC2 上の MySQL にデータを import する
- 集計結果を CSV や Google スプレッドシート等で経理に提供する
ここで会計上の集計ロジックは集計プログラムや SQL 文内に(WHERE や JOIN で)埋め込まれることになり、場合によっては複雑な SQL を書かなければならない。
主な課題とその解決策
上記の会計データ基盤は単純かつ安上がりだったが、会社や事業の成長に従って幾つか無視できない課題が生じた。
- 集計に時間がかかる
- 元データの UPDATE やスキーマ変更に弱い
- データの整合性を保つコストが高い
まず 1. の集計に時間がかかる問題について。
事業の成長に従って集計対象のデータ量が増加するだけでなく、中間テーブルの生成や集計時の JOIN が増えて集計が徐々に重くなっていったことで時間がかかるようになってしまった。EC2 のそれなりに良いインスタンスを使っていたかと思うが、集計時間が徐々に伸び月次決算に間に合わないことが増えてきた。
解決策としては、シンプルにお金で解決することになった。当時インフラに AWS を使っており、 EC2 上の MySQL から Redshift という DWH 製品に移行した。ここで Google の BigQuery を使うという案もあったのだが、クエリの書き換えなど移行コストの低さから Redshift を選択した。BigQuery や Redshift は(様々な機能があるが)一般的なデータベースと比較した際の主たる特徴として、ストレージ内でのデータの配置が一般的なデータベースのような行指向ではなく列指向であり、1 行ごとの INSERT や UPDATE が苦手な代わりに特定の列が示す値を全て取得し合算するような集計を高速に処理できる。
次に 2. の元データ変更に弱い問題について。
この会計データ基盤では本番のデータ構造をそのまま使い、集計条件を SQL 文内で指定していた。しかし元データの全てが immutable ではないため、集計後に仕様や障害対応で UPDATE されると再集計時に差分が生じてしまうことがあった。また、新たな機能やサービスが追加されたときにスキーマの変更を把握してそれに対応したクエリを書かなければ必要なデータを集計することができない。
本来はデータ構造を会計の要件に合わせて変えたい(理想をいえば全てのテーブルが履歴形式で immutable だと嬉しい)のだが現実的には困難なため、解決策としては対症療法に終始することになった。具体例としては、社内の issue テンプレートに「会計に影響があるか」という項目を入れておき、会計データ基盤の存在を布教する(知らなければ質問が来て、知っている人は自力で解決できる。まずは存在を認知してもらうことが重要)ということをやっていた。他には社内の Slack において新しいチャンネル作成イベントを全て監視・通知し、新規開発が始まりそうであれば早めに話を聞いて会計への影響を判断し注意点を説明するなど地道な活動をしていた。
最後に 3. のデータの整合性を保つコストが高い問題について。
会計データ基盤では、個別の取引と全体の残高という二つの視点でデータ間の整合性を求められる。
例えば、決済代行会社に対する債権について考えてみる。素朴にお金の流れを整理すると、ある月末時点における債権残高は次の計算式で表現できる。
前月末残高 + 当月変動額 = 当月末残高当月変動額は以下のように分解できる。
当月変動額 = 当月決済額 - 決済代行手数料 - 当月入金額まずはこの各項目に対応するデータが正確に保存・集計できているかという「取引レベルの整合性」が求められる。
次に、各項目を足し引きした計算結果として得られる当月末残高があるべき残高と整合しているかどうかという「残高レベルの整合性」が求められる。因果関係で考えると取引は原因であり残高は結果で、原因を基に生成した仕訳を入力して得られた数字をあるべき残高と突合することで確かめる。つまり「既に認識している債権債務の変動要素」が正しいことを取引レベルで確かめ、その上で「その認識に見落としがないか」を残高レベルの整合性を確認することで保証する。
残高の整合性が満たされていないケースとしては、「債権債務に変動があるものの、会計データとして捕捉していない」という見落としが考えられる。例えば決済代行会社の管理画面で決済をキャンセルして顧客に返金しているが、(決済代行会社には記録が残っているものの)会社の DB にはデータが残っていないというケースが考えられる。
何年も運用しているシステムだとそのような見落としがあれば(あるべき残高と会計上の残高が乖離していくため)気づくことができるが、事前に全てを網羅的に把握することは難しい。特に、会社と顧客の関係としては解決されているが会計で必要なデータが残っていない(もしくはどこにあるのか整理されていない)という場合、問題を認識するところから始める必要があるので解決に時間を要する。そもそも問題として認識されておらず、残高差異が異常値を示してから問題となるのが最悪なパターンである。
これを防ぐためには、より短いサイクルで「取引を集計した結果の残高」と「あるべき残高」を比較して残高差異の要因を究明し潰していく必要がある。なぜならば、差異の原因が増えれば増えるほど原因の確定が難しくなるため。そのためにも、突合作業をできるだけ自動化することが望ましい。
解決策としては、決済や配送の取引先からの請求額と一致する明細と突合可能な本番のデータを合わせて会計データ基盤のデータベースに import し突合するようにした。結果としてはこのような会計データ基盤ができた。
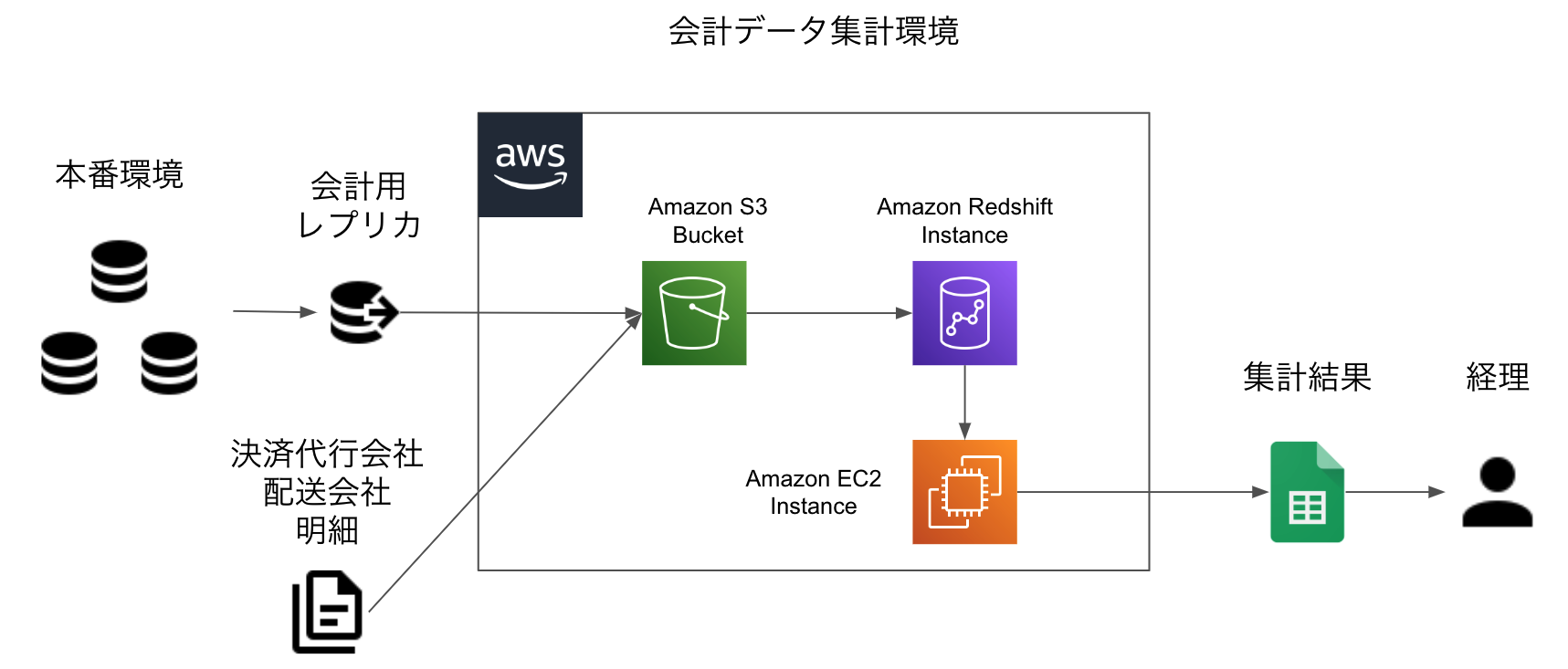
基本的なデータの収集・集計の手順としては従来と変わらないが、他社から受け取った明細も含めて一旦 S3 にデータをため Digdag と Embulk で Redshift にロードすることになった。
原則として毎月残高レベルの整合性をチェックし、問題があれば決済や配送の明細を使って全件突合し集計クエリで捕捉できていない理由を調べてフィードバックする、という作業をやっていた。
内部統制や監査への対応
会計データ基盤が出力するデータは財務諸表の根拠となるので、会計監査や内部統制報告制度への対応を考慮しなければならない。一口に内部統制と言っても様々な目的や枠組みがあるのだが、ここでは金融商品取引法に基づく「財務報告の信頼性を担保する」ための仕組みを指すものとする。
財務報告の信頼性を担保するために、財務報告の元データを生み出すシステムに関わるシステムや業務プロセスを対象として、開発者は経理や内部監査と協力し監視や統制の仕組みを整備・運用する。
上記で述べたような会計データ基盤では具体的に、以下のような対応が必要となると考えられる。
- 開発、権限付与プロセスを明文化する
- どのような役割の人間が業務に関係しているか
- 業務処理の過程で誰による何の承認が必要か
- 例: システムの変更管理やインフラ環境へのアクセス権限付与は PdM の承認が必要…など
- いつでも過去の出力結果を再現できるようにデータのバックアップを取っておく
- システムの変更後に過去のデータから過去の出力結果を正確に再現できるかテストする
- BS 上の勘定科目のあるべき残高と、会計データ基盤上の集計結果を突合する
- 上記全てが適切に運用されていることを示す証拠を保存する
何をもって内部統制が有効とみなされるかというのは状況によって異なるが、上記のような取り組みはこのような会計データ基盤を作る時に必要になると思う。
基本的な方針としては、一人で勝手に財務諸表につながる数字を改竄できないように、または改竄されても簡単に検出できるような仕組みを整備して運用し、その証拠を保存していくことになる。
証拠を保存するのは面倒だが、リリースの承認証跡であれば JIRA 等の issue tracker で管理しつつそのステータスや GitHub PR の特定のラベルをチェックしてから自動で merge → deploy するとか、インフラへのアクセス権限管理であれば Terraform のようなソフトウェアで自動化するなど工夫の余地はある。
アーキテクチャの移行
主な課題を解決したかに見えた会計データ基盤だったが、全社的にマイクロサービスをやっていくぞということで、データベースを dump して集計する方式を続けることが難しくなった。
難しい理由としては、以下の 2 点が挙げられる。
- データベースが分散しているため、データ集めてくるのが面倒になる(困難)
- 個々のサービスのデータ構造やコンテキストを把握して集計クエリを書かなければならない(無理)
一つ目の理由は、単純にデータベースが分散するからで、それに加えてアーキテクチャが異なる(各サービスは自分たちで何のデータベースを使うか決めることができる)多数のデータベースの dump を受け取って加工し集計するのが難しいから。
二つ目の理由は、各サービスは他のサービスに対してインターフェイスを公開してそれを守る限り内部実装はチーム内に閉じて行うため、そのデータ構造をチーム外の人間が集計のために把握しなければならないというのがそもそもマイクロサービス化の方針に逆行しているから。
チーム内外での議論の結果として、会計データ基盤も一つのマイクロサービスとして捉え、責務を明確にしてそれをインターフェイスとして定義することになった。
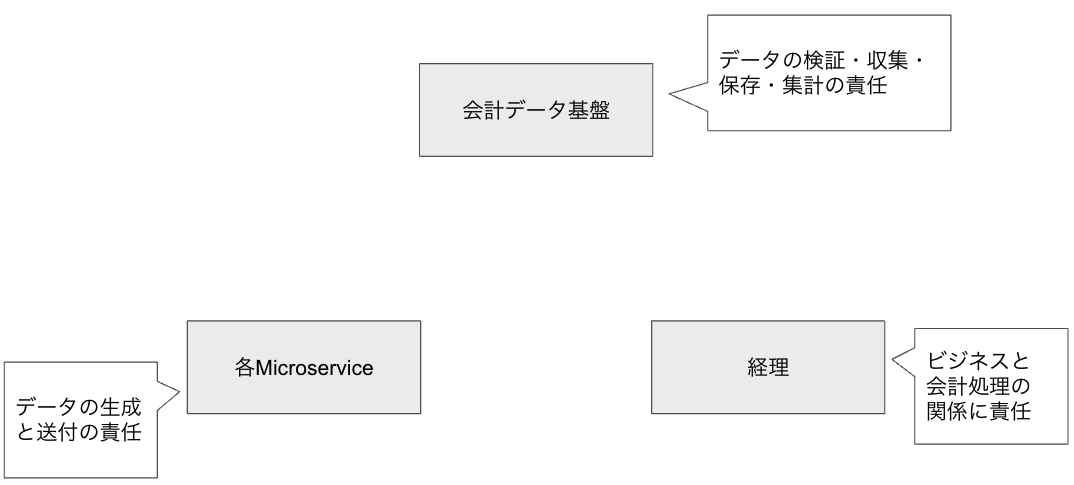
会計データ基盤の関係者は以下の三者に分類することができる。
- 経理や財務
- 会計データ基盤のサービス
- その他のマイクロサービス(会計サービスのクライアントとなる)
サービス全体に関する正確な財務情報を適時に報告するという業務において、それぞれの関係者の責任は次のように分担できると考えられる(組織構造によって変わるかもしれない)。
それぞれの責任を遂行するために、各々の役割は次のように分担できる。
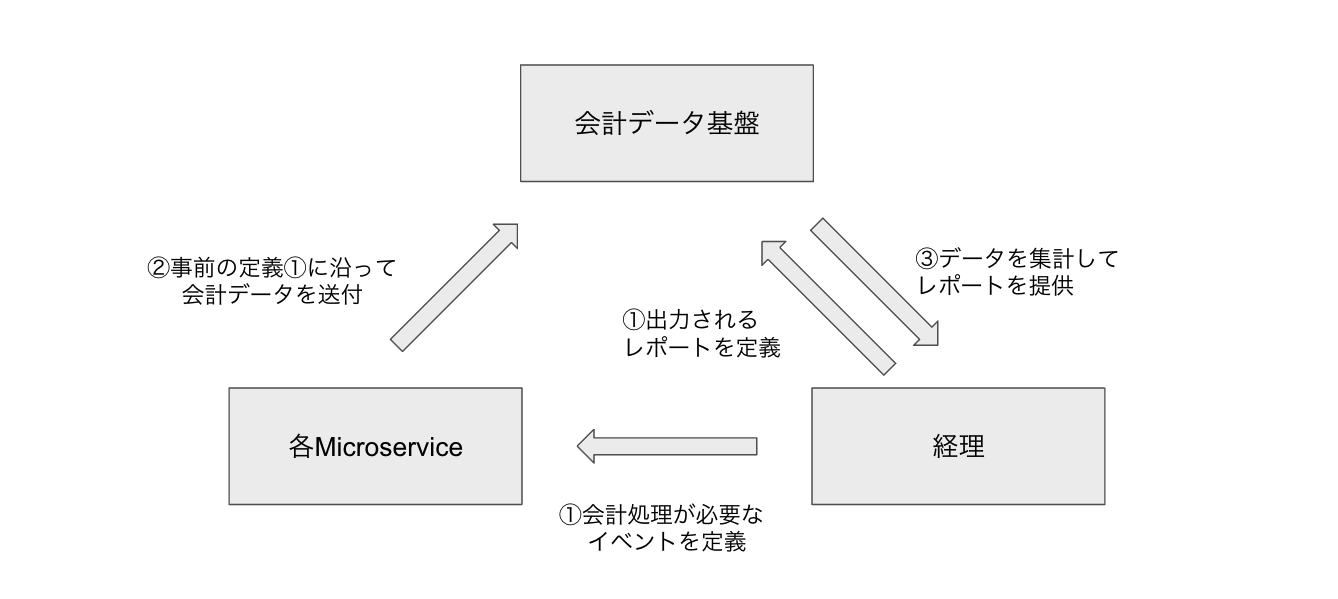
この役割に沿ってデータの収集と検証、集計をするための会計データ基盤を構築した。
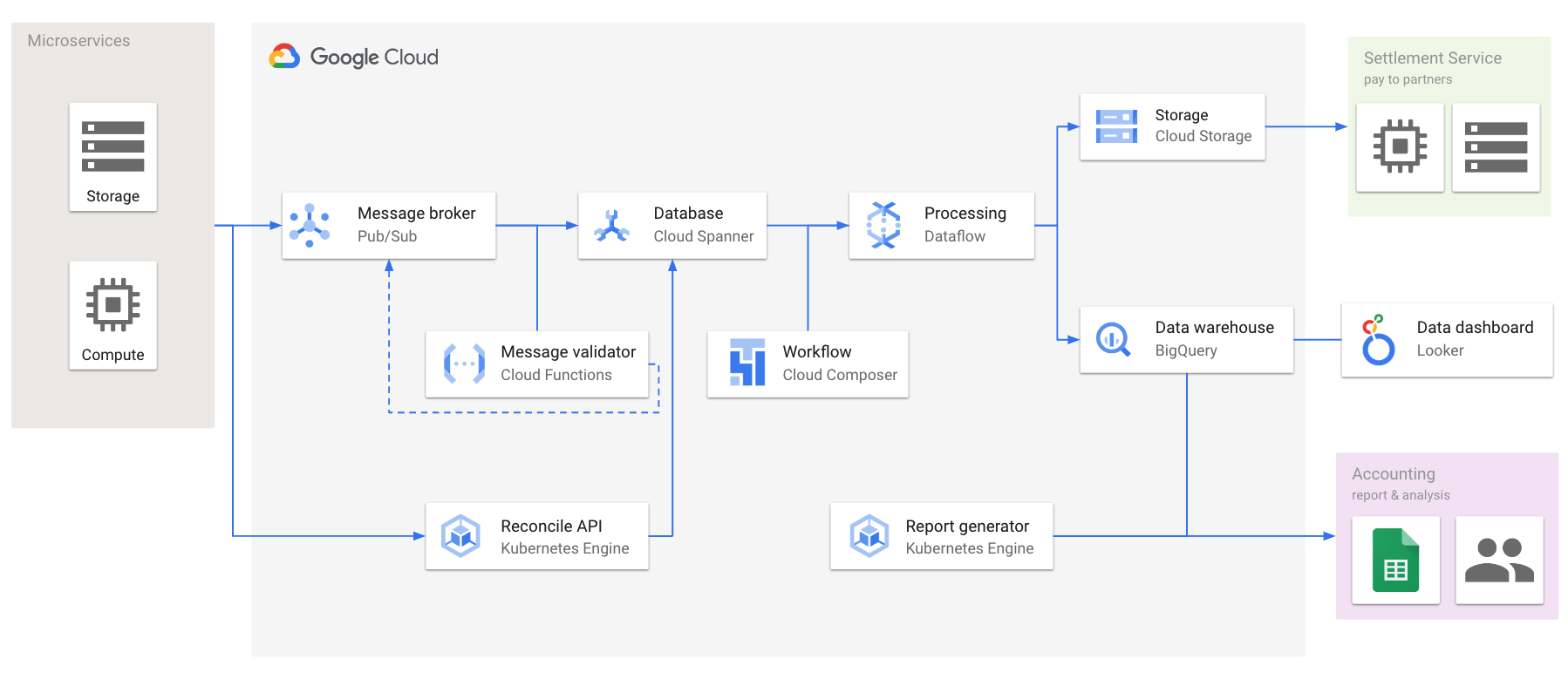
従来は AWS を使っていたが、このときは社内のマイクロサービスで Google Cloud の利用を前提に様々な支援の仕組みが構築されていたので Google Cloud を使って構築することになった。
集計までの手順
上記の会計データ基盤では従来の dump して取り込む形式とは異なり、会計処理のためのデータを予め定義したインターフェイスに沿って生成して送ってもらう必要がある。サービス全体の可用性を重視し、データを受け取る際は Pub/Sub モデルを活用して非同期で処理することになった。
また、会計のデータを集計して支払いやレポートに使う際に際にクライアント側のマイクロサービスとの不整合が起きないよう突合処理(Reconcile と呼ばれていた)用の API を用意し、それをクライアント側から呼んでもらうことで不整合を検知できるようにした。
まずデータのやり取りをする前に、以下のような事前の準備が必要となる。
- 経理チームがクライアントとなる各マイクロサービスに送付してもらうデータの形式と最終的に得たいレポートの形式を定義する
- 会計データ基盤側では上記の定義に従ってデータの検証や集計に用いるマスターデータを投入する
- 各マイクロサービスはデータの生成、保存や送付、突合処理の開発を行う
実際のデータ送付や検証、集計は次の手順で行われる。
- 経理による定義に沿って各マイクロサービスが指定の Cloud Pub/Sub へ会計処理に必要なデータを送る
- 届いたデータを subscribe し、定義されたインターフェイスに沿って Cloud Functions で検証する
- 検証結果が正しければ Cloud Spanner に書き込む
- 誤っていれば Pub/Sub のエラー用 topic に書き戻す
- 各マイクロサービスは定期的にバッチ処理で突合 API を通じてマイクロサービス側で保存しているデータと会計データ基盤側のデータを突合する
- ここで突合済みのデータは社外への支払いや会計のレポート集計に使われる
- Spanner に保存したデータを Dataflow で BigQuery に運ぶ
- また、社外への支払いで使うデータを Cloud Storage にエクスポートしておく
- 月次で BigQuery から会計のレポートを集計する
レポート以外のちょっとした数字の可視化については BigQuery を Looker から見られるようにしておき、必要に応じて経理の側で Looker 上にダッシュボードなどを作ってもらうようにした。
成果と課題
このようなデータ基盤を構築したことで、以下の成果があった。
- 分散したデータベースに適した集計環境が得られた
- (JOIN やサブクエリ、中間テーブルが必要なくなり)集計が高速化した
- データに関する知識の面で個人への依存度が低下した
3 についてだが、従来の(本番データの複製から SQL で集計する)方式では、集計ロジックを考えて実装する人間に本番環境のデータ構造と会計知識の両方が要求されていた。これは当然で、例えば「完了した取引に付随して発生した決済代行手数料」を集計しようとすると、完了した取引や決済はデータベース上でどのように表されているか、更にそれぞれの状態遷移の仕様を把握して会計の要件に沿ったクエリを書かなければならない。
新たな方式では「事業上のイベントと会計処理の関係」と「事業上のイベントと実際のデータとの関係」を把握する責任を組織的に分担することができるので、何か問題が起きたときに原因の分析や対応を組織的なアプローチ(根回し)で解決できるようになり個人の頑張りへの依存度が低下した。
一方で、作った後に以下のような課題も見えてきた。
- 組織的な責任分担の浸透
- クライアント実装のコスト
- 運用や障害対応
まず 1 について。新たな方式では経理、会計データ基盤、そして各マイクロサービスがそれぞれの役割を果たさなければ正しい会計情報を適時に報告できなくなる。そのように設計したのだから当然といえば当然なのだが、理解度や信頼度が異なるそれぞれのチームの関係者にこういう仕組みがあるのでこのような仕事をお願いしますと言って回るのは面倒だった。
次に 2 について。新たな方式ではデータベースを dump して集計する方式と異なり、会計で必要なデータを生成・保存・送付するための開発コストが必要になる。1 の問題と関係するのだが、新規サービスの開発中に「実は会計の対応もお願いしたいんですが…」と伝えるのは心苦しかった。やってもらわないと会計で捕捉できないのでやってもらうのだが、クライアント実装を簡単にするような仕組み(SDK のような)があると良かったなと思った。
最後に 3 について。従来の方式ではデータベースの dump をバッチ処理で加工、ロード、集計していたのでインフラの運用作業は少なかったが、新しい方式ではリアルタイムで各マイクロサービスが送ってくるデータを受け取って検証し保存しなければならないので、監視や障害対応などの運用作業が増える。
私はこれらの課題が解決される前に退職してしまったのだが、今頃は解消・軽減されているかもしれない。
会場で頂いた質問
このアーキテクチャに際して、当日会場で「(会計データ基盤にとってクライアントとなる)マイクロサービス達が正しいデータを送ってきていることをどのようにして確認していたのか?」という質問を頂いた。
確かに、従来の本番データのレプリカ及びそれを加工したデータを SQL で集計する方式では、ある程度の整合性を保ったデータをソースとして使うことができる。一方で、新しい方式では正しいデータが会計データ基盤に送られない場合、(顧客との関係においてサービスが適切に運営されていたとしても)それを基にした会計処理は行われないということになる。
この質問への回答としては、常に 2 種類の整合性をチェックするということが言える。
- 取引レベルの整合性: 送られたデータが全て届いており保存されているか
- 残高レベルの整合性: 送られたデータを集計した結果があるべき残高と整合しているか
1 については突合用の API を用意して、それをクライアント側から呼んでもらうことで解決する。このとき「クライアント側にあってデータ基盤側にない」と「クライアント側になくてデータ基盤側にある」という 2 種類の不整合が生じる可能性がある。バグや仕様の認識誤り、障害など様々な原因があるので、不整合が生じる度に原因を調査して潰していく必要がある。
2 については、社内外に存在する突合先データと会計データ基盤の集計結果を突合することで解決する。例えばフリマアプリであれば顧客の売上金残高は社内で管理されているはずなので、会計データ基盤に送られたデータから集計した売上金残高と本番のデータベースで管理している売上金残高を(顧客の id ごとに)突合し、差異を検出したら原因を調査する。決済代行手数料や配送料の未払残高であれば、取引先からの請求書やその明細と突合する。
ここは更に工夫の余地があって、例えばあるイベントが送られるときは必ず特定のイベントも送られる、というような場合ではそれを検証時にチェックするなり事後的にバッチ処理で突合するなどで検出することができる。
それぞれのアーキテクチャの特徴と pros/cons
最初に紹介したデータベースを dump する方式を Query-Driven、次に紹介した予め定義されたインターフェースに沿ってデータを送ってもらう方式を Event-Driven と呼ぶことにし、それぞれの pros/cons を整理する。
手順の違い
Query-Driven な方式では既存のデータを使ったバッチ処理で、Event-Driven な方式は会計用のインターフェイスを定義したストリーミング(リアルタイム)処理ということができる。

トレードオフ
Query-Driven な方式は開発を始めるのが簡単だが事業が成長、複雑化していくにつれて徐々に短所が目立ってくる。特にクエリが複雑になりがちという問題が大きい。
逆に Event-Driven 方式では予め定義されたインターフェイスに沿ってデータが送付されそれを一括で集計するだけなので単純なクエリで済む一方、事前の準備や開発の手間が多いという問題がある。

参考事例: Uber
上記のトレードオフにより、サービスが大規模かつ複雑になるほど Event-Driven な仕組みへの移行動機が強まると考えられる。実際にそのような過程を辿った中で最大の公開されている事例としては Uber を挙げることができる。
同社ではライドシェアの他に宅配やトラック輸送など複数の需給マッチングプラットフォームを運営しており、それぞれにパートナーや顧客との取引がある。上記のブログによるとライドシェアだけで年間 400 億件の仕訳があるそうだ。FY2021 決算の投資家向けプレゼンテーションを見ると年間の Gross Booking ARR(顧客が払う料金の年額)は 1,000 億ドル近い。
元々はデータベースに書き込まれたデータを DWH に流し込む ETL パイプラインを作り、そこから SQL で会計処理に必要な数値を集計していた。
(画像は上記の記事より引用)
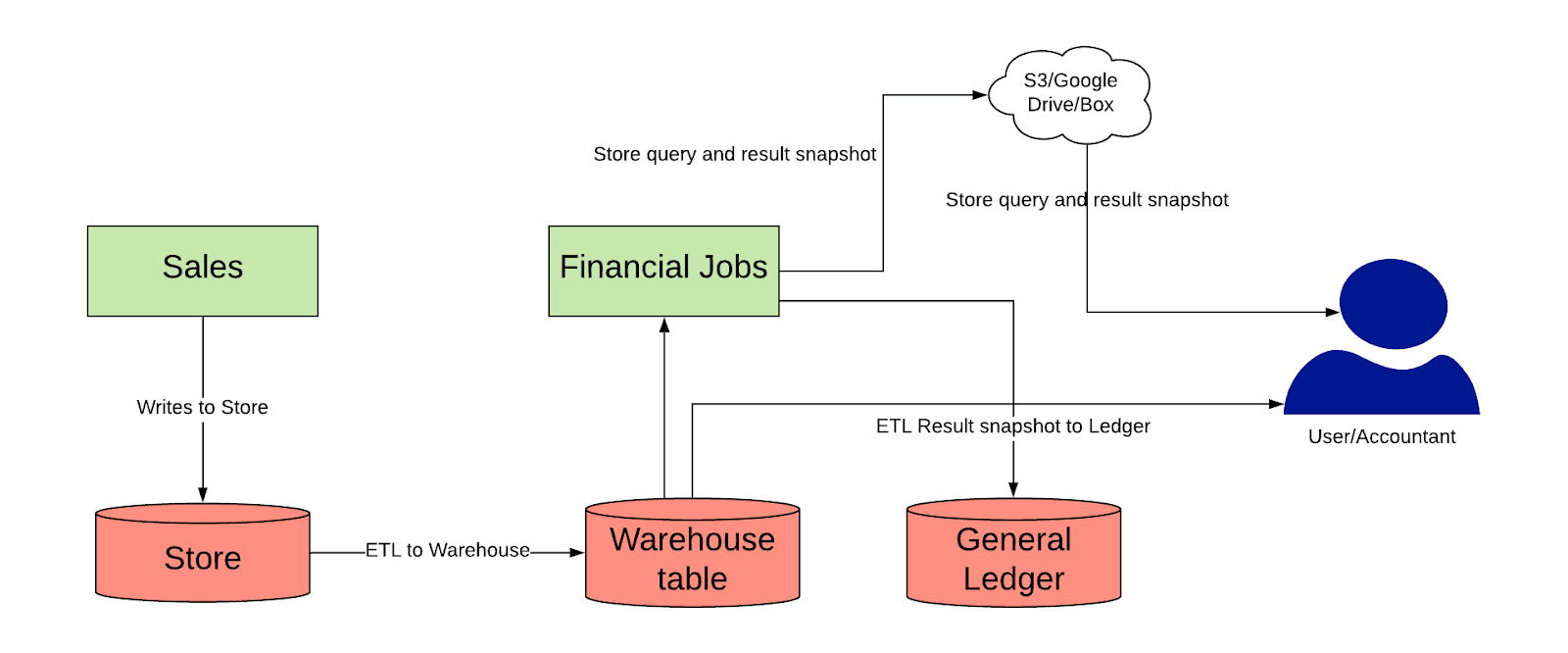
しかし、クエリの複雑化などの理由から下記のような Event-Driven なアーキテクチャに移行した。コンポーネントの詳細な説明は上記の記事を参照。
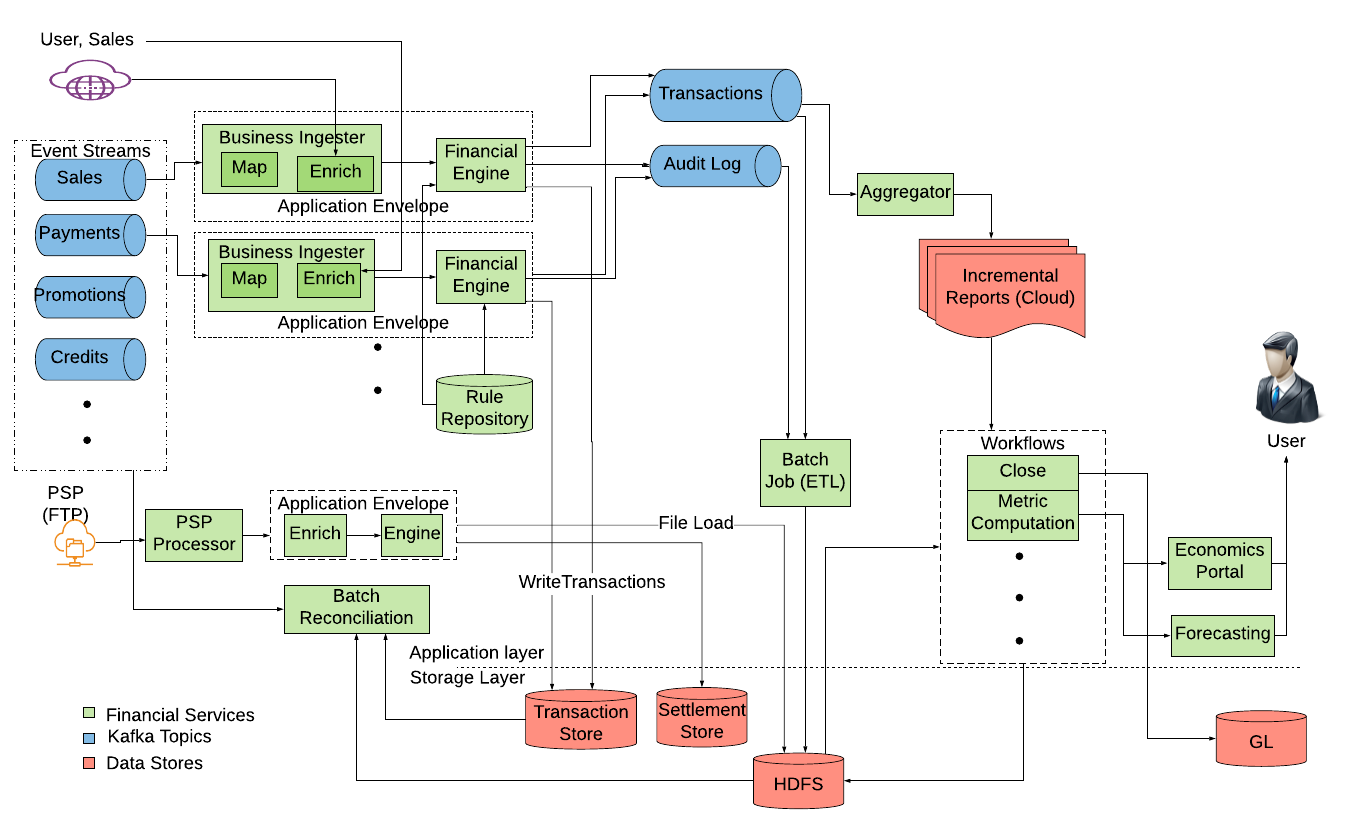
Uber 社では記事にもあるように、事業の内容に応じて財務上のライフサイクルを定義してその中から会計に関連するイベントを抽出し、それが発生したタイミングで同期的・非同期的に会計データ基盤(同社では FCP: Financial Compute Platform と呼んでいる)へデータを送る。
例として、ライドシェアでは次のような会計に関連するイベントが挙げられている。
- 顧客が乗車した時の利用料金
- プロモーションコード利用による割引
- Uber の決済システムから顧客への請求
- 決済代行事業者からの決済完了通知
- 決済代行事業者からの代金支払
- ドライバーへの支払
Event-Driven の隠れた?恩恵として、リアルタイムな処理がしやすくなり、例えば Uber のようなライドシェアでは乗車・日・都市といった様々な粒度でより短い間隔で収益性やプロモーションの影響を分析できるというメリットがある。
同社には Financial Engineering と呼ばれているチームがあり、財務データを用いて事業上の重要指標を予測しつつそれを最適化するための予算配分を行なっているらしい。本記事とは関係ないので詳細は触れないが、事業 KPI の関連性をグラフ構造で定義して目標値から入力となる(広告やクレジット等の)予算を最適化するという手法は面白いのでご興味のある方はぜひ。
会計特有の課題について
会計データ基盤にどのようなアーキテクチャや製品を選択するとしても、会計というドメインそのものに由来する本質的な課題は変わらない。会計データ基盤が直面する課題は主に次の三種類に分けることができる。
- 履歴形式のデータを用意する
- 内外の整合性を保つ
- 内部統制に配慮する
まず、会計に使うデータは原則的に履歴形式とするのがよい。
集計対象となるサービスのデータ構造が履歴形式になっていない場合は、スナップショットを使うなど工夫が必要となる。会計に必要な全てのデータが immutable なレコードとして記録されている場合は問題ないが、サービスの仕様によっては immutable なデータのみを使ってサービスを作っていくのが大変なので現実的には難しい。
次に、内外の整合性を保つことについて。
会計処理を積み重ねていくと財務諸表になる。この財務諸表内のそれぞれの項目があるべき残高と整合しているかは、その項目が示す債権債務の相手先に依存する。例えば自社プラットフォーム内で管理されている顧客への債権債務残高であれば自社でそれを集計する必要があるし、取引先への債権債務ならば請求書や残高確認状などが突合先になる。仕訳を積み重ねた結果がそれらと整合しているか突合することで会計処理の網羅性を確認することができる。
最後に内部統制について。
会社法上の大会社や特定の条件を満たす会社では会計監査人による財務諸表監査を受けなければならない。このとき、財務報告に重要な虚偽表示が存在しないことを監査する過程で、財務報告に係る情報システムの開発・運用プロセスが適切に整備、運用されているかが評価される。J-SOX とか ITAC/ITGC などと呼ばれている。具体的にどのような業務が必要になるかは状況によるが、「一人で好き勝手にシステムや数字を改竄できない、改竄してもすぐに検知できる」ことや「業務の証拠や承認の証跡を必ず残す」ことに気をつけて適時に専門家のレビューを受けていれば特に大きな問題に発展することはない。
会計データ基盤を作る際の方針
会計に限らずデータ基盤を作って運用するときに最適な構造は、対象となるドメインの特徴やそのデータの利活用パターンによって異なる。しかし、サービスを開始して間もない等の理由でそれらが見定められていない場合は、とにかく早く安く作るのが重要なので会計データ基盤に時間をかけすぎるのは良くないと考えられる。
この点、BigQuery や Redshift などの DWH 製品は使いやすく高速に集計でき、最近は値段が安くなったり新しい機能が積極的に追加されてるためおすすめできる。
そのため、最初は本記事でいう Query-Driven な仕組み(本番のデータを ETL パイプラインで DWH に運び、 SQL で頑張って集計する)からはじめ、事業の規模が拡大したり複雑化したら Event-Driven な仕組みを検討し始めるという方針がおすすめだ。
最後に
自分はもともと経理の仕事をしていたのが本記事のような会計データ基盤でプロダクトマネージャーの仕事をするようになり今ではプログラマーをやっているのだが、その理由として以下の 2 点がある。
- 本記事のような「会計データを集計する仕組み」を自分で PdM ではなく一人のプログラマーとして一から作りたい
- もしそれが上手くいかなくても、会計とプログラミング両方の知識や経験があれば当分の間は食いっぱぐれなさそう
この記事をご覧になって興味ある方がいたらぜひお話ししたいです。