graphql/dataloader を読んだ話
graphql/dataloader のドキュメント及びソースコードを全て読んだので、その話を書く。
読むことにした第一の理由は仕事で使うからだが、以下の特徴から自分のプログラミング学習教材として適していそうだと考えたからでもある。
- 広く使われている OSS である
- GitHub の星が 11k
- npm trends で検索しても多くの人がダウンロードしている
- コードの量が少ない
- 実装は src/index.js に全て書かれている
- コメント含めて 500 行にも満たず、しかもその 1/3 くらいはコメント
- テストカバレッジが高い
- 常に 100%
- 初めて読むコードでテストカバレッジが高いと、テストコードを読むことで期待される挙動を確認できるので嬉しい
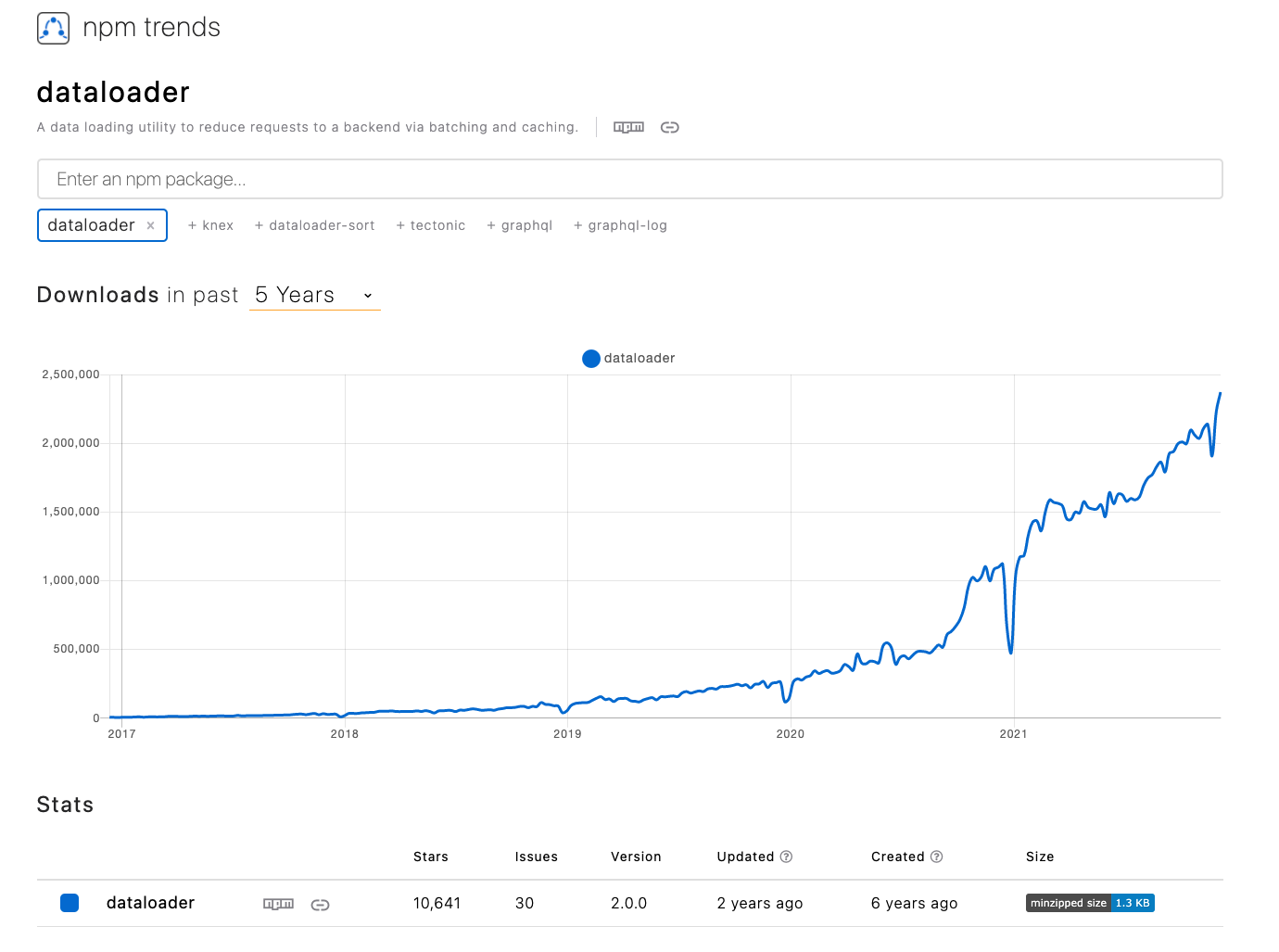
npm trends によると、一週間で 200 万件近くダウンロードされているようだ。
目次
- graphql/dataloader とは
- 主要な機能
- Why Using with GraphQL
- 詳細な実装
- DataLoader の基本的な使い方
- DataLoader について書かれた記事
- 勉強になった点
- 本記事のまとめ
graphql/dataloader とは
graphql/dataloader はアプリケーションのデータ取得に使用される汎用的なユーティリティであり、データソースからのデータ取得を Batch 処理したり結果を Cache するための簡単な API を提供する。これにより、データ取得リクエストを大幅に効率化することができる。
元のアイデアは Facebook (現 Meta)社内で 2010 年に開発された “Loader” API で、これは当時存在していた様々な KVS の back-end API からデータを取得する方法を統一するために開発された。この “Loader” API を簡略化し Node.js アプリケーション等で使えるよう JavaScript で実装したのが graphql/dataloader で、現在は GraphQL Foundation によって MIT ライセンスで公開されている。
アイデアとしては Facebook の Production 環境で使われている仕組みと同じだが、このリポジトリのコードはあくまで参考実装であり Facebook で使われているわけではない。当時 Facebook では PHP で同様の機構が実装されていたようだ。
主に GraphQL サービスの構築に使われているが、特定のアーキテクチャやデータソースに依存するような実装にはなっていない。なお、GraphQL サービスのパフォーマンスを向上させるためには何かしら同じような仕組みが必要になる(詳しくは後述)ので、JavaScript に限らず様々な言語で様々な実装がされている。1
ちなみに graphql/dataloader を最初に書いた Lee Byron と Dan Schafer は Facebook 社で GraphQL を開発したメンバーでもある。
主要な機能
README を読むと、 graphql/dataloader には Batch と Cache の 2 つの機能があることが分かる。
Batch
データ取得のリクエストを一定時間待ち、その間に行われたリクエストを統合して Batch 処理する。
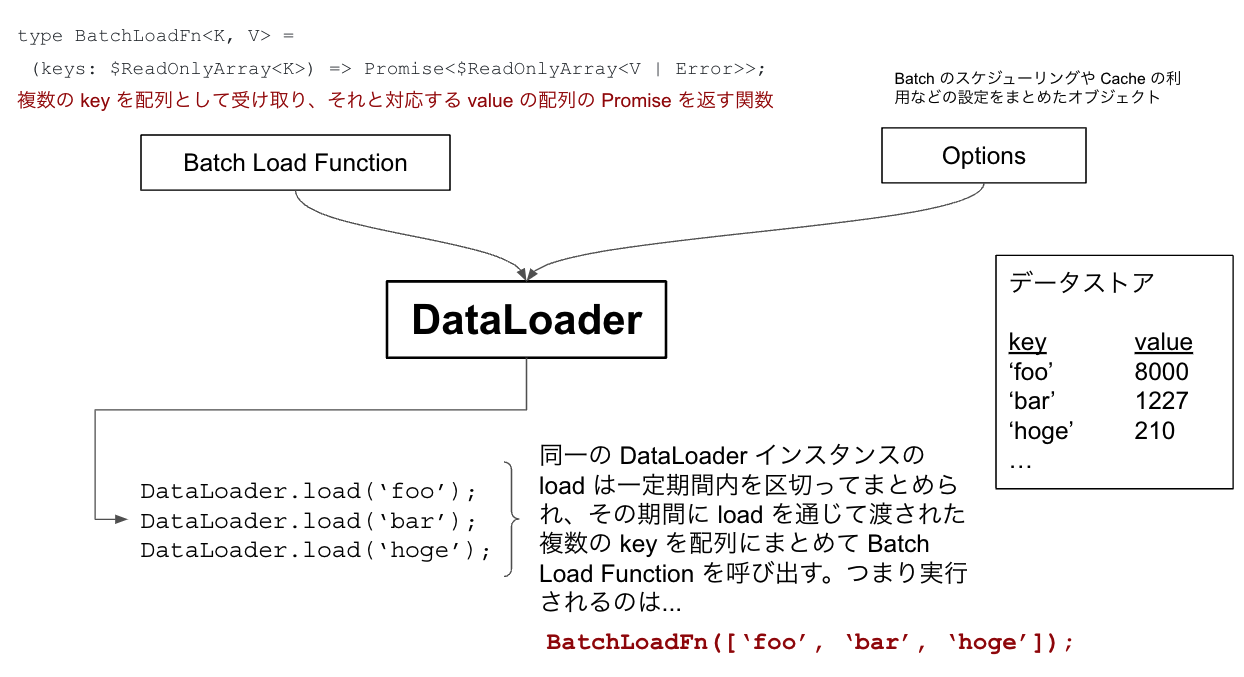
使う側は Batch Function と呼ばれる関数を自身で定義して DataLoader のコンストラクタへ渡す。この関数は Batch 処理対象となる key の配列を受け取り、その key と対応する value(もしくは Error)の配列の Promise を返すようにしておく。つまり…
type BatchFunction<K, V> = (
keys: $ReadOnlyArray<K>
) => Promise<$ReadOnlyArray<V | Error>>;実際に Batch Function をどのように定義するかは、リポジトリの examples/SQL.md が分かりやすいかもしれない。
const DataLoader = require("dataloader");
const sqlite3 = require("sqlite3");
const db = new sqlite3.Database("./to/your/db.sql");
// Dispatch a WHERE-IN query, ensuring response has rows in correct order.
const userLoader = new DataLoader(
(ids) =>
new Promise((resolve, reject) => {
db.all(
"SELECT * FROM users WHERE id IN $ids",
{ $ids: ids },
(error, rows) => {
if (error) {
reject(error);
} else {
resolve(
ids.map(
(id) =>
rows.find((row) => row.id === id) ||
new Error(`Row not found: ${id}`)
)
);
}
}
);
})
);
// Usage
const promise1 = userLoader.load("1234");
const promise2 = userLoader.load("5678");
const [user1, user2] = await Promise.all([promise1, promise2]);
console.log(user1, user2);上記の ids => new Promise((resolve, reject) => { db.all(...) } が Batch Function であり、何のことはない key の配列を受け取って value もしくは Error の配列(の Promise)を返すだけの関数である。
DataLoader.load に取得対象の key を渡して呼び出すと、 Batch Scheduling 内(デフォルトはイベントループ内の 1 tick。詳しくは後述)に行われたデータ取得リクエストの key を集めた配列を引数に Batch Function を呼び出し、結果として key に対応する value の配列の Promise を返す。
「Batch Function は key 配列を受け取って value の配列の Promise を返す」が「DataLoader.load では単一の key を取りそれと対応する value の Promise を返す」という構造が肝で、ユーザー側としては key を渡して load するだけで裏側で DataLoader が一定時間分の key をまとめて Batch Function に配列として渡し、まとめてデータベースにリクエストを送ってくれる。
この DataLoader.load はアプリケーションの複数の箇所から呼び出される可能性があるが、同一の DataLoader インスタンスからの load であれば Batch 処理(と結果の Cache が)できる。
GraphQL の Resolver ではこれが非常に重要で、 DataLoader を使うと簡単に非同期 Resolver による N+1 問題を回避することができる。2
DataLoader の Batch 処理を簡単に図解すると、次のようになる。
Batch の実行範囲
DateLoader.load(key) はデフォルト 1 tick ごとに key を配列にまとめ Batch Function を呼ぶ。
ここで 1 tick とはどういう意味か。graphql/dataloader は Batch Scheduling に Node.js の process.nextTick() を使っており、これに渡したコールバックは呼び出し時点のイベントループ内の phase に関わらず次の phase、つまり C/C++ ハンドラが JavaScript を実行するタイミング、の前に実行される。
具体的には、下図のそれぞれの箱の中で process.nextTick() にコールバックを渡すと、各箱に固有の処理が行われたあと次の箱に進む前にそれが呼ばれる。

上図は https://nodejs.org/en/docs/guides/event-loop-timers-and-nexttick/#event-loop-explained から引用。
Batch が実行されるタイミングを自分で決めたい(例えば 16ms 後に実行する、とか)場合は batchScheduleFn を定義して DataLoader のコンストラクタに渡せばよい。詳しくは README の Batch Scheduling を参照。
Cache
Batch と並ぶ graphql/dataloader の主要な機能として Cache がある。
これは Batch に登録される key とそれに対応する value の Promise の組をメモ化する。
これにより、同一の DataLoader インスタンスから実行された(≒ 同一のリクエストにおける) Batch 内で同一の key で複数回 value を取得しようとするとき、二回目以降のデータ取得リクエストには Cache から value の Promise を返すことができるようになる。これにより、データ取得のパフォーマンスが大きく向上する。
Cache はデフォルトで es6 から追加された Map を使う。Cache 内の key と value の組み合わせは load する度に無限に増えていくので、 DataLoader インスタンスの寿命が長い場合はメモリを大量に消費する可能性があり安全ではない。
ただし、 DataLoader インスタンスは原則的にリクエスト単位で作られるので、クライアントにレスポンスを返した後は DataLoader インスタンスへの参照がなくなり GC によってメモリが解放されるので、問題が起きる可能性は少ない。
リクエスト毎に DataLoader インスタンスを作る理由は Cache を適切に扱うためで、仮にリクエスト間でこれを共有すると異なるリクエストのデータ取得結果が Cache としてそれぞれのクライアントから見えてしまい適切ではない。これは DataLoader を使うにあたって非常に重要な点で、例えば GraphQL と合わせて使う場合はリクエスト毎の context に attach することになると考えられる。
以上の背景から、もし Cache の生存期間を長くしたい場合はカスタムの Cache をクライアントごとに生成することを検討すべきだろう。その場合は DataLoader のコンストラクタで cacheMap として自分が使いたい Cache のインスタンスを渡せばよい。詳しくは README の Custom Cache を参照。
Cache の key は通常 string 等のスカラ値だが、オブジェクトを使うことも許容されている。その場合は Cache の key となるオブジェクトから実際に key と value (の Promise)の組を取り出す関数である cacheKeyFn を定義して DataLoader のコンストラクタに渡す必要がある。このとき、DataLoader は cacheKeyFn の返り値を Cache とみなす。
Why Using with GraphQL
DataLoader は GraphQL サービスの構築によく使われる。この理由は GraphQL のドキュメントをよく読んでいくと分かる。
GraphQL のクエリにおける各フィールドの値は、 Resolver と呼ばれる関数によって取得される。フィールドに文字列や数値などスカラ値が生成される場合は実行が完了し、オブジェクトが生成される場合はそのオブジェクトに含まれるフィールドを更に Resolve し、これをスカラ値に達するまで続ける。つまり GraphQL のクエリは必ずスカラ値に到達する。3
Resolver がデータベースを読み書きする場合、これは通常 Promise を返す非同期関数となる。GraphQL はフィールドに値が生成されることを期待しており、非同期 Resolver が完了するのを待ってから「optimal concurrency」で処理を続行する。4
During execution, GraphQL will wait for Promises, Futures, and Tasks to complete before continuing and will do so with optimal concurrency.
ここで Resolver が Promise の配列を返すとき、 GraphQL は全ての Promise を並行して(concurrently)待つ。
それに加え、フィールドがオブジェクトの配列である場合、オブジェクトの各フィールドを解決するために処理を続行する。つまり、配列でオブジェクトを返すときはその配列要素ごとに Resolver が実行される。5
つまり、これらの仕様を無視して素朴に GraphQL サービスを構築すると、フィールドが解決される度に新しいデータベースへのリクエストが発生してしまい、いわゆる N+1 問題が起きる。
文章だけだと分かりにくいので具体例を用意した。例えば、次のような GraphQL スキーマがあると仮定する。
# 顧客
type Customer {
id: ID
orders: [Order!]!
}
# 顧客による注文
type Order {
id: ID
items: [Item!]!
amount: Int
}
# 注文される商品
type Item {
id: ID
name: String
description: String
price: Int
}
type Query {
customer(id: ID!): Customer
}このときある id を持つ顧客の注文一覧とそれぞれで注文された商品を取得するクエリは次のようになるだろう。
query GetOrdersAndItems {
customer(id: 'foobar') {
id
orders {
items {
name
description
price
}
amount
}
}
}GraphQL の各 Resolver が非同期かつ DataLoader を使わず個別に SQL データベースから注文や商品を取得するような実装になっている場合、次のような SQL が発行されると考えられる(あくまで例です)。
-- 1. 顧客 id を使って注文を探す
SELECT item_id, amount FROM orders WHERE customer_id = "foobar";
-- 2. 1 の結果として得た item_id から各商品を探す
SELECT name, description, price FROM items WHERE id = "hoge";
SELECT name, description, price FROM items WHERE id = "fuga";
SELECT name, description, price FROM items WHERE id = "piyo";
-- 以下、2 が注文された商品数だけ実行されるこれに対して DataLoader が提供する Batch や Cache の API を介してデータを取得するとデータベースのアクセスを大幅に減らすことができ、計算資源の節約やパフォーマンスの向上に繋がる。例えば上記の 2. であれば、
-- 2. 1 の結果として得た item_id から各商品を探す
SELECT
name, description, price
FROM
items
WHERE
id IN ("hoge", "fuga", "piyo");のようなクエリが一回だけ発行される(上記はあくまで例であり、実際にどのようなクエリが発行されるかは実装によります)。こちらの方がデータベースへのアクセスやクエリ結果の処理が少ないので、データベースへの負荷が低くレスポンスも速い。
graphql/dataloader の実装は特定のアーキテクチャに依存しないが、 GraphQL の Resolver で非同期処理をすると容易に非効率なクエリが発行されてしまうので、それを防ぐため GraphQL サービスに使われることが多い。
実は graphql/dataloader や類似のライブラリ以外にも GraphQL でこのような N+1 問題を解決する方法はあるのだが、個人的にはこれが最も単純明快な解決策だと思う。
詳細な実装
ここからは v2.0.0 の src/index.js を上から順に読んでいく。
YouTube の DataLoader - Source code walkthrough の動画が非常に参考になる。この動画は v1 の解説なので最新の v2 とは若干の差があるが、基本的に大きな違いはない。6
DataLoader flow type: L10-L33
graphql/dataloader では JavaScript に静的な型を付けるために Flow を使用している。
index.js では最初に以下の 3 つの type が定義されている。まずは BatchLoadFn で、これは Batch 処理の対象 keys K を受け取って Values V の配列の Promise を返す関数。
// A Function, which when given an Array of keys, returns a Promise of an Array
// of values or Errors.
export type BatchLoadFn<K, V> = (
keys: $ReadOnlyArray<K>
) => Promise<$ReadOnlyArray<V | Error>>;次に定義されているのは Options で、これにより DataLoader クラスのコンストラクタで初期値を設定できる。例えば Batch の最大サイズや Cache を使うかどうか等の設定をすることができる。
// Optionally turn off batching or caching or provide a cache key function or a
// custom cache instance.
export type Options<K, V, C = K> = {
batch?: boolean;
maxBatchSize?: number;
batchScheduleFn?: (callback: () => void) => void;
cache?: boolean;
cacheKeyFn?: (key: K) => C;
cacheMap?: CacheMap<C, Promise<V>> | null;
};最後に CacheMap で、これは通常は使うことはないが、カスタムの Cache を定義したいときはこの型を持つインスタンスを Options として渡す。7
// If a custom cache is provided, it must be of this type (a subset of ES6 Map).
export type CacheMap<K, V> = {
get(key: K): V | void;
set(key: K, value: V): any;
delete(key: K): any;
clear(): any;
};type 定義は ES6 で追加された Map の subset になっている。
DataLoader コンストラクタ: L34-L70
DataLoader のコンストラクタは BatchLoadFn と Options を受け取る。BatchLoadFn は前述の通り Batch 処理対象となる key の配列を受け取って配列の Promise を返す関数で、ユーザーが定義する。
コンストラクタから呼ばれる関数(getValidMaxBatchSize など)については後述する。
load: L71-L113
単一の key を受け取り、それを Batch Function に与えて得られる value の Promise を返す。 value そのものは返さない。
行数はかなり多いが責任は単純で、
- まず引数の key が null でも undefined でもないことを確かめる
getCurrentBatchで load を実行する Batch 処理を取得する- 引数の key で Cache (key と対応する value の Promise)が存在するかを調べ、hit すればそれを返し hit しなければ Batch 処理に key を push してから key と Promise の組み合わせを Cache する
- 3 の Promise を返す
という処理を行なっている。
load や loadMany をまとめて Batch 処理を実行するのは dispatchBatch という別の関数で、これは 2. の getCurrentBatch から呼ばれる。
loadMany: L114-L148
引数として複数の key を受け取り、それを Batch Function に引数として与えて得る value の配列の Promise を返す。 value の配列そのものは返さない。
基本的には DataLoader.load を Promise.all でラップした関数と考えてよい。つまり…
var [a, b] = await myLoader.loadMany(["a", "b"]);上記のコードは、下記のコードとほぼ同じ動作をする。
var [a, b] = await Promise.all([myLoader.load("a"), myLoader.load("b")]);異なる点としては、 load が失敗した際に Promise.all ではまとめて reject するが、 loadMany では Error インスタンスを resolve する。
clear, clearAll: L149-L174
clear では key を指定して、それと対応する Cache を消去する。この Cache は DataLoader インスタンスごとに作られている。
clear(key: K): this {
var cacheMap = this._cacheMap;
if (cacheMap) {
var cacheKey = this._cacheKeyFn(key);
cacheMap.delete(cacheKey);
}
return this;
}積極的に Cache をクリアせずともメモリが枯渇する可能性は非常に低い。なぜなら、基本的には DataLoader インスタンスはリクエスト毎に作られ結果がクライアントに送られた後(参照がなくなるので) GC によってメモリが解放されるからだ。
実際にこれを使う場面としては、 GraphQL の Mutation 等で key に対応する value が変わって前の Cache を消したいときだろう。
clearAll は DataLoader インスタンスの Cache を全て消去する。
clearAll(): this {
var cacheMap = this._cacheMap;
if (cacheMap) {
cacheMap.clear();
}
return this;
}prime: L175-L205
引数として指定した key と value を Cache に書き込む。つまり load することなく Cache を使うことができる。
value が Error インスタンスの場合は reject された Promise を Cache する。また、既に指定された key に対して何らかの value が Cache されている場合は何もしないので、上書きしたければ clear してから prime を呼び出す必要がある。
これは load や loadMany によって書き込まれた Cache と挙動を揃えるため。
enqueuePostPromiseJob: L206-L246
デフォルトの Batch Scheduling を定義する。
DataLoader のコンストラクタで batchScheduleFn を渡さない場合、この enqueuePostPromiseJob で Batch 処理のスケジューリングを行う。その場合、この関数は次の手順で呼び出される。
DataLoader.loadがgetCurrentBatchを呼ぶgetCurrentBatchは dispatch 待機中の Batch が無い場合、新しい Batch を作る- この時、
DataLoader._batchScheduleFnのコールバックとしてdispatchBatchを呼び新しく作った Batch を実行する- この時デフォルトで使われる
_batchScheduleFnがこのenqueuePostPromiseJob
- この時デフォルトで使われる
実装としては次のようになっている。
var enqueuePostPromiseJob =
typeof process === "object" && typeof process.nextTick === "function"
? function (fn) {
if (!resolvedPromise) {
resolvedPromise = Promise.resolve();
}
resolvedPromise.then(() => {
process.nextTick(fn);
});
}
: setImmediate || setTimeout;
// Private: cached resolved Promise instance
var resolvedPromise;Node.js 環境では process.nextTick が使われる。nextTick に渡したコールバックは Node.js におけるイベントループ内の各 phase の終了時に実行される。各 phase には実行するコールバックの FIFO キューがあり、その phase に固有の operation を実行した後キューがなくなるかコールバックの最大数に達するまでコールバックを実行する。
ここでは Promise の then コールバックで process.nextTick を呼び出しているが、これは他の Promise より前に nextTick が呼ばれないようにするため。この技法は解説動画の 23:55~ で説明されている。
process.nextTick の注意点としては、全てのコールバックが nextTick を呼んだ時点の phase 終了後イベントループを継続する前に呼ばれるので、再帰的に呼び続けると I/O が実行できなくなる恐れがある。イベントループについて詳しくは Node.js のドキュメントを参照。
- Don’t Block the Event Loop (or the Worker Pool)
- The Node.js Event Loop, Timers, and process.nextTick()
下記の Synk 社のブログも参考になる。
なおブラウザ環境には Node.js の process.nextTick が無いので、 setImmediate や setTimeout を介して同様の処理が実行される。この場合、パフォーマンスが少し落ちる可能性がある。
Batch flow type: L247-L257
ユーザーが定義する Batch Function の実行状況に責任を持つオブジェクトの型を定義している。
type Batch<K, V> = {
hasDispatched: boolean; // batch が dispatch されたかどうかのステータス
keys: Array<K>; // batch function に与える key の配列
callbacks: Array<{
// batch promise の完了時に実行される callback
resolve: (value: V) => void;
reject: (error: Error) => void;
}>;
cacheHits?: Array<() => void>;
};getCurrentBatch: L258-L287
DataLoader インスタンスを引数に取り、 Batch (の実行状況)を返す。
返す Batch はまだ dispatch されていない待機中の Batch があるかどうかによって 2 種類に分かれる。
ある: その Batch を返すなし: 新しい Batch オブジェクトを作り、それをdispatchBatchで実行する
なお、待機中の Batch にはコンストラクタで設定できる maxBatchSize に到達するまで取得対象の key を追加し続けることができる。 maxBatchSize のデフォルトは Infinity だが、実際には次の tick で Batch が dispatch されるので無限に追加されていくことはない。
getCurrentBatch という名前だが、この関数の責任としては Batch を作成したり返すだけでなく(この関数が load から呼ばれることで)Batch を dispatch することも含まれている。
dispatchBatch: L288-L352
これも行数は多いが責任は単純で、
- Batch の発行ステータス(hasDispatched)を true にする
- load 対象の key 配列が空であれば Cache を返す
- load 対象の key があれば、 key を与えて Batch Function を実行する
- Batch Function が不正、または実行そのものに失敗した場合は failedDispatch を呼ぶ
- 成功した場合は結果が配列かつ与えた key と同じ長さであることを確かめ、個々の value の型(Error インスタンスかどうか)に沿って reject または resolve していく
この dispatchBatch を呼んでいるのは getCurrentBatch のみで、これを呼んでいるのは load のみなので、 DataLoader.load を呼んだ時は次のような手順で dispatch される。
- getCurrentBatch を呼んで dispatch されていない待機中の Batch があるか確認する
- 待機中の Batch があれば、そこに取得対象の key を追加する
- なければ新しく作って dispatch し、そこに取得対象の key を追加する
Batch の実行間隔はデフォルト 1 tick で、コンストラクタから渡せる batchScheduleFn でカスタマイズできる。
failedDispatch: L353-L367
Batch 実行に失敗したときに key と対応する Cache を消して、 Batch に登録された callback の Promise を reject する。
これは Batch Function に与える key 毎に行われる。もし Cache に hit した場合は(Batch の実行に失敗しても)Cache を返して resolve する。
// Private: do not cache individual loads if the entire batch dispatch fails,
// but still reject each request so they do not hang.
function failedDispatch<K, V>(
loader: DataLoader<K, V, any>,
batch: Batch<K, V>,
error: Error
) {
// Cache hits are resolved, even though the batch failed.
resolveCacheHits(batch);
for (var i = 0; i < batch.keys.length; i++) {
loader.clear(batch.keys[i]);
batch.callbacks[i].reject(error);
}
}Batch 失敗時に Cache を消す理由は、呼び出し側で reject を捕捉してリトライしたときに Cache hit しないようにするため。
resolveCacheHits: L368-L376
Batch を引数に取り、その中で Cache に hit した Promise を resolve するだけの関数。
getValidMaxBatchSize: L377-L394
DataLoader のコンストラクタから呼び出され、 Batch の最大サイズを返す。デフォルトは Infinity。
// Private: given the DataLoader's options, produce a valid max batch size.
function getValidMaxBatchSize(options: ?Options<any, any, any>): number {
var shouldBatch = !options || options.batch !== false;
if (!shouldBatch) {
return 1;
}
var maxBatchSize = options && options.maxBatchSize;
if (maxBatchSize === undefined) {
return Infinity;
}
if (typeof maxBatchSize !== 'number' || maxBatchSize < 1) {
throw new TypeError(
`maxBatchSize must be a positive number: ${(maxBatchSize: any)}`
);
}
return maxBatchSize;
}Batch の最大サイズを制限すると、 getCurrentBatch で待機中の Batch をより細かく切り分けて実行することができる。
getValidBatchScheduleFn: L395-L410
DataLoader のコンストラクタから呼び出され、 Batch を Schedule する関数を返す。
デフォルトでは enqueuePostPromiseJob を使う。
// Private
function getValidBatchScheduleFn(
options: ?Options<any, any, any>
): (() => void) => void {
var batchScheduleFn = options && options.batchScheduleFn;
if (batchScheduleFn === undefined) {
return enqueuePostPromiseJob;
}
if (typeof batchScheduleFn !== 'function') {
throw new TypeError(
`batchScheduleFn must be a function: ${(batchScheduleFn: any)}`
);
}
return batchScheduleFn;
}getValidCacheKeyFn: L411-L422
DataLoader のコンストラクタから呼び出され、 key を通じて Cache から key と value の組み合わせを取得する関数を返す。
デフォルトは (key => key: any); を返す。
// Private: given the DataLoader's options, produce a cache key function.
function getValidCacheKeyFn<K, C>(options: ?Options<K, any, C>): (K => C) {
var cacheKeyFn = options && options.cacheKeyFn;
if (cacheKeyFn === undefined) {
return (key => key: any);
}
if (typeof cacheKeyFn !== 'function') {
throw new TypeError(`cacheKeyFn must be a function: ${(cacheKeyFn: any)}`);
}
return cacheKeyFn;
}key が string や number であればデフォルトで問題ないが、オブジェクトを key として使いたい場合は CacheKeyFn が必要になってくる。例えば MongoDB など。
getValidCacheMap: L423-L447
DataLoader のコンストラクタから呼び出され、 Cache を書き込むためのインスタンスを返す。コンストラクタに渡すオプションで Cache を無効にすることもでき、その場合はこの関数が null を返す。
デフォルトでは ES6 で追加された Map オブジェクトを使う。
isArrayLike: L448-L458
引数が配列かどうかを boolean で返す関数で、下記の 2 箇所で使われている。
- loadMany に key の配列を与えたときそれが配列でなければ例外を投げる
- dispatchBatch において、 Batch Function の Promise を resolve した結果が配列でなければ例外を投げる
isArrayLike 関数に次のような引数を与えると、各行にコメントで記した結果を返す。
undefined // false
null // false
'x' // false
[] // true
['x'] // true
['x', 'y', 'z'] // true
[{'foo': 100, 'bar': 200}, {'foo': 300, 'bar': 400}] // true
[null, null, null] // true最後の条件では配列がその最後の要素を持つかどうかを判定している。
x.length > 0 && Object.prototype.hasOwnProperty.call(x, x.length - 1);ロジックだけ読むと何のためかよく分からないのだが、 Object.prototype が上書きされた場合に安全に配列の要素を参照するためかもしれない。
参考: https://sosukesuzuki.dev/posts/stage-3-object-hasown/
DataLoader の基本的な使い方
- まずは Batch Function を定義する
- 取得対象のデータを示す key の配列を受け取り、それと対応する value 配列の Promise を返す
- Batch Function をコンストラクタに渡して
DataLoaderのインスタンスを作る - データを取得するときは
DataLoader.load(key)を使う- これにより、同じ Batch Scheduling 内に行われたデータ取得リクエストを DataLoader が一つにまとめてくれる(参考)
- 実際の挙動としては Batch Function に key の配列が渡されて実行される
- load は引数として与えた key に対応する value の Promise を返す
DataLoaderインスタンスごとにCacheの Map が作られる- key とそれに対応する value の Promise の組が入っている
- 異なるクライアントのリクエストを Cache すると見えてはいけないものが見えてしまうので、必ずリクエスト毎あるいはクライアント毎に DataLoader インスタンスを作ること
DataLoader について書かれた記事
最後に DataLoader について書かれた記事を紹介する。実際に graphql/dataloader を使ってはいなくとも、基本的なアイデアとしては共通している。
- mercari engineering: メルカリ Shops での NestJS を使った GraphQL Server の実装
- クラスメソッド: [GraphQL] N+1 問題を解決する DataLoader の仕組みとサンプル実装
- Qiita: GraphQL と N+1 SQL 問題と dataloader
- Zenn: TypeScript * GraphQL のバックエンド設計プラクティス
- Zenn: GraphQL で N+1 問題を解決する4つのアプローチ
- 最適化されたデータの取得をしてくれる Dataloader の仕組みを調べてみた
勉強になった点
graphql/dataloader は自分自身のプログラミングの勉強になったので、感想を書いておく。
これは簡潔かつ短いコードで限られた機能を提供しているが、非常に多くの人に使われている。多くの人に使われている理由は、 GraphQL の非同期 Resolver で出会う可能性が非常に高い問題を簡単に解決できるからだろう。
それを簡単に解決できる理由としては、大元のアイデア(一定時間内のデータ取得リクエストを Batch 処理としてまとめ、データソースへのリクエスト回数を減らす)が単純に優れているだけでなく、アイデアを実現するために graphql/dataloader が責任を持つ範囲を明確に限定しているという点を挙げたい。
graphql/dataloader の責任はデータ取得リクエストの Batch とその Cache であり、その中でも一部に限られている。 Batch 処理を行う関数はユーザー側が定義して DataLoader コンストラクタに渡す。Batch も Cache もインターフェイスは決まっているが、それさえ守ればユーザー側でカスタマイズできる。
特定のアーキテクチャに依存するのはユーザーが実装する Batch Function やユーザーが与える CacheMap であり、 graphql/dataloader 自体は非同期でサービス内の様々な箇所から同じデータベースに向けて効率的なデータ取得要求をしたいというユースケースを上手に抽象化し、特定のアーキテクチャに依存しない実装となっている。これは簡単で分かりやすく、使いやすい設計といえる。
機能に関して言えば、このような DataLoader は ORM の機能として実現することもできる(例えば Prisma のように)。しかし、 graphql/dataloader のように小さく責任範囲が明確で上手に実装されているライブラリは、実装を把握するのが簡単、組み込みやすい、取り替えやすいなど様々なメリットがあると考えられる。
少人数で大きな価値を生み出すにはこのようにプログラムの責任を明確にしていくことが重要だと感じたので、自分もこれを心がけていきたい。
本記事のまとめ
- graphql/dataloader の本質は Batch と Cache の機能を提供する簡潔な API
- GraphQL におけるデータ取得の問題を簡単に解決してくれるのでよく使われる
- 単純かつ率直な実装で素晴らしいアイデアを実装しており、プログラミングの参考になる
本記事に誤りがあれば Twitter の DM や GitHub の連絡先へのメール等で教えていただけると助かります。どうぞよろしくお願いいたします。
最後に、今回 Node.js の非同期処理について調べていて最も自分に刺さった言葉を置いておきます。
the way that you should be doing things should be easy in the way you shouldn’t be doing things should be difficult
— Ryan Dahl: Node JS, JSConf.eu 2009
Footnotes
-
他言語による実装では Go の graph-gophers/dataloader や Ruby の exAspArk/batch-loader、Shopify/graphql-batch がよく使われているようだ。 ↩
-
ただし Batch Function 内部で N+1 問題を引き起こすようなループ処理内でのクエリ発行を行っている場合は、当然ながら N+1 問題が発生してしまう。もっとも、これは GraphQL の Resolver が起こすそれに比べればコード上で明確なぶん与しやすそうだ。 ↩
-
https://graphql.org/learn/execution/#asynchronous-resolvers ↩
-
load や loadMany には v2.0.0 で breaking change があるので、詳しく知りたい場合は Releases/v2.0.0 を見ると良い。 ↩
-
DataLoader の Cache はデフォルトで無限に成長し、 DataLoader インスタンスへの参照がなくなったときに GC によってメモリが解放される。通常はリクエスト単位でインスタンスを作るので、 Cache は GC されメモリがすぐ解放されるため問題になることはない。開発者 Lee Byron 氏の解説動画 10:19 ~によれば、 Facebook でもそのような実装になっているようだ。 ↩